In today’s data-driven world, access to accurate and timely information is paramount. Introducing our latest innovation – YL Web Scraper, a versatile tool designed to effortlessly extract data from any webpage. With a streamlined process consisting of just three steps – Input URL, Specify XPath, and View Data – YL Web Scraper revolutionizes the way you gather information online.
Step 1: Input URL
Getting started with YL Web Scraper is a breeze. Simply launch the application and paste the URL of the webpage you wish to extract data from. Whether it’s a news article, a product catalog, or a research paper, YL Web Scraper can handle it all.
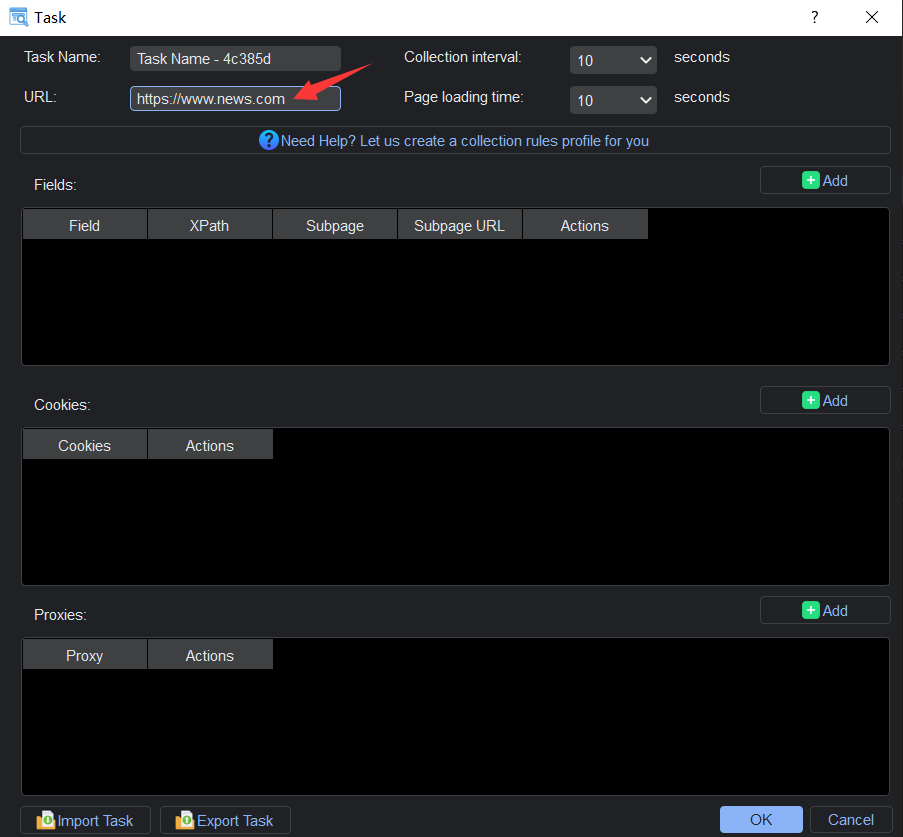
Step 2: Specify XPath
Now comes the heart of the operation. YL Web Scraper empowers you to pinpoint exactly which elements of the webpage you want to extract. Using XPath, a powerful language for navigating XML documents, you can select specific elements such as text, images, links, and more.
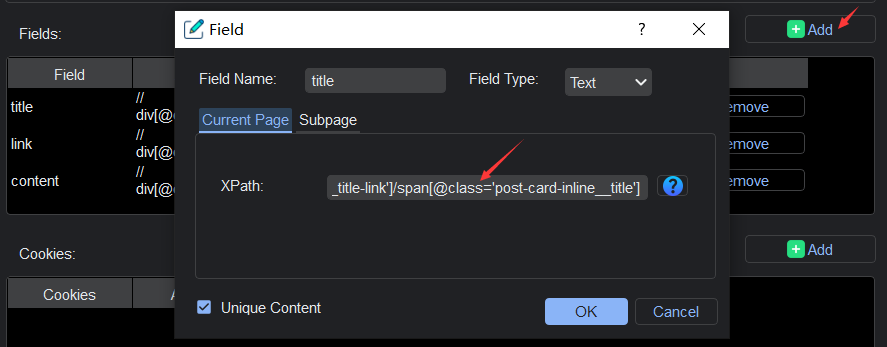
For example, if you’re interested in gathering product information from an e-commerce site, you can specify the XPath to target the product name, price, and description. The flexibility of XPath ensures that you get precisely the data you need.
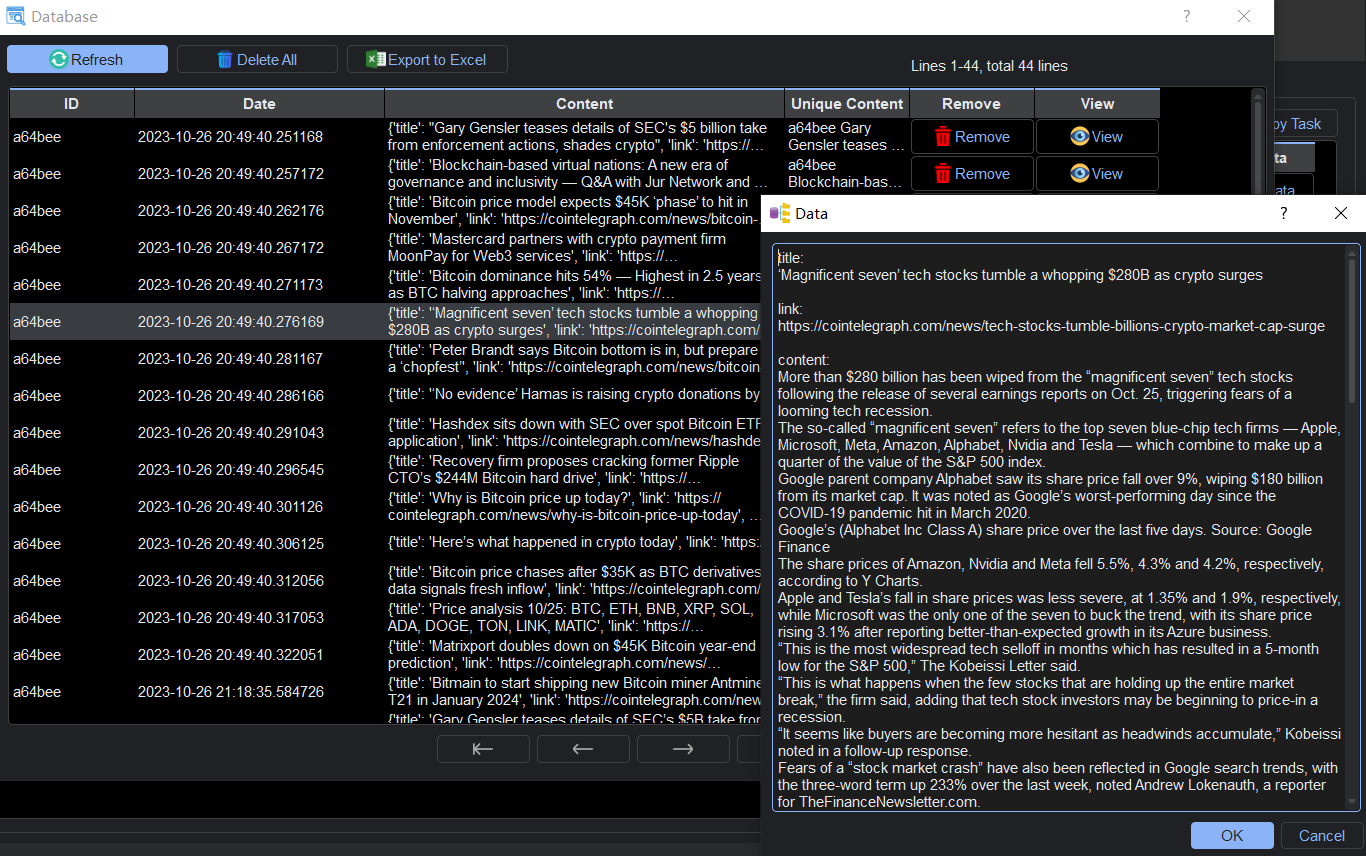
Step 3: View Data
Once you’ve defined your XPath expressions, YL Web Scraper works its magic. In seconds, it scours the webpage, extracts the specified data, and presents it to you in a clean, organized format. Say goodbye to manual copying and pasting; YL Web Scraper automates the entire process, saving you time and effort.
The user-friendly interface of YL Web Scraper makes it easy to navigate through the extracted data. You can preview the results, apply filters, and export the information in various formats like CSV, Excel, or JSON, ensuring compatibility with your preferred data analysis tools.
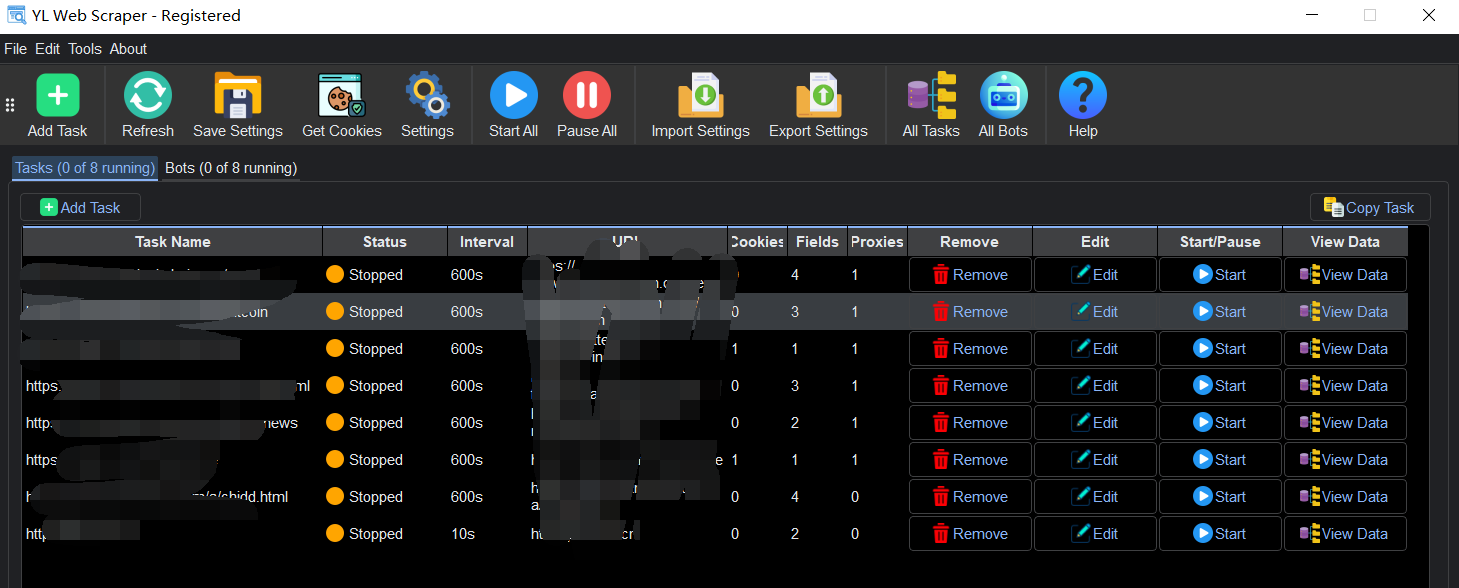
Additional Features
YL Web Scraper goes above and beyond in ensuring a seamless data extraction experience:
Multi-Page Scraping: Need to collect data from multiple pages? YL Web Scraper can handle it. Simply set up pagination rules, and let the software do the rest.
Scheduled Scraping: Automate your data collection tasks by scheduling them to run at specific times. This feature ensures that you receive fresh and up-to-date information whenever you need it.
Customizable Output: Tailor the output format to suit your needs. Whether it’s a detailed report or a concise summary, YL Web Scraper provides the flexibility to adapt to your specific requirements.
Conclusion
YL Web Scraper empowers users to unlock valuable insights from the vast expanse of the internet. Its intuitive interface, robust XPath capabilities, and additional features make it a must-have tool for researchers, analysts, and businesses seeking to stay ahead in the information age.
Say goodbye to manual data extraction and embrace the future of web scraping with YL Web Scraper. Try it today and experience the difference for yourself. Your data-driven journey starts here.