In today’s data-driven world, the ability to extract information from various websites is a crucial skill for businesses and individuals alike. YL Web Scraper, our latest product, empowers users to effortlessly gather data from any webpage. What sets it apart is its robust support for HTTP, HTTPS, SOCKS5, and other proxies, ensuring seamless access to target websites. In this guide, we’ll walk you through the steps to harness the full potential of YL Web Scraper by utilizing proxies.
Step 1: Inputting the Target URL The first step in using YL Web Scraper is to provide the URL of the webpage you want to scrape. Simply enter the URL into the designated field within the application’s user-friendly interface.

Step 2: Defining XPath for Data Extraction YL Web Scraper offers the flexibility to select precisely what data you want to collect. Utilizing XPath, a powerful language for navigating and extracting data from XML documents, you can specify the elements on the webpage that you’re interested in. This allows for precise and customized data extraction tailored to your specific needs.
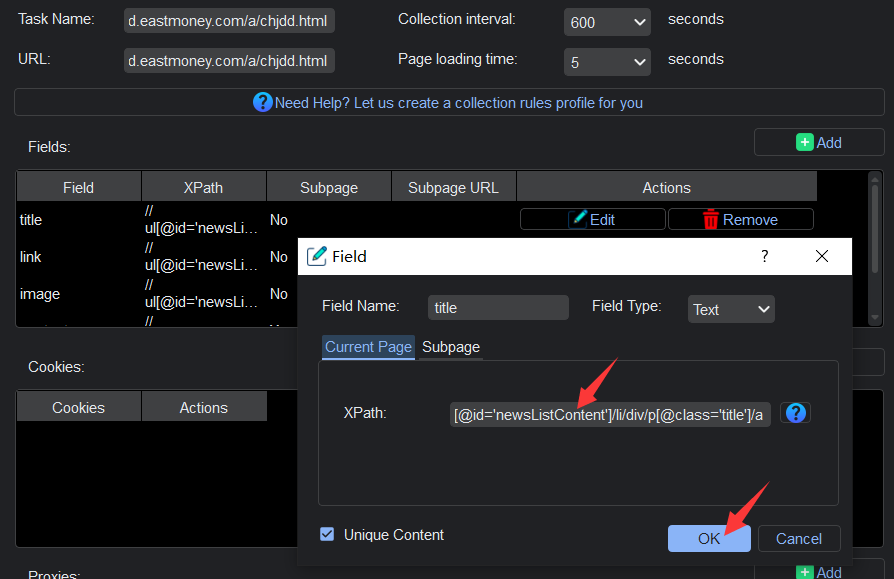
Step 3: Configuring Proxies for Access One of the standout features of YL Web Scraper is its seamless integration with various proxy protocols. This enables users to access websites through HTTP, HTTPS, SOCKS5, and more. To set up proxies, navigate to the proxy configuration section within the application. Here, you can input the necessary proxy details, including the IP address and port.
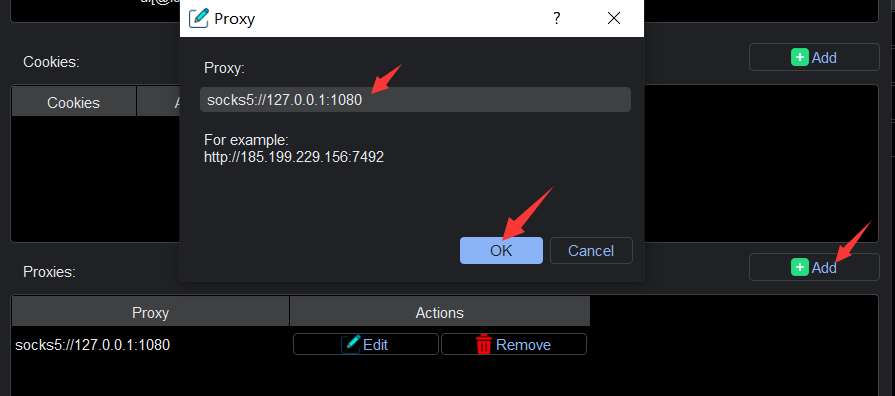
Step 4: Selecting and Implementing Proxies YL Web Scraper supports both single and multiple proxies, allowing for a high degree of flexibility in your scraping endeavors. You can choose to utilize a single proxy for your session or employ multiple proxies to distribute the load and increase efficiency. This versatility ensures that you can adapt your scraping strategy to suit the demands of your specific project.
Step 5: Initiating Data Collection and Viewing Results With the URL, XPath, and proxies set up, you’re ready to initiate the data scraping process. YL Web Scraper will execute the operation, gathering the specified information from the target webpage. Once the scraping is complete, you can conveniently view and export the collected data within the application.

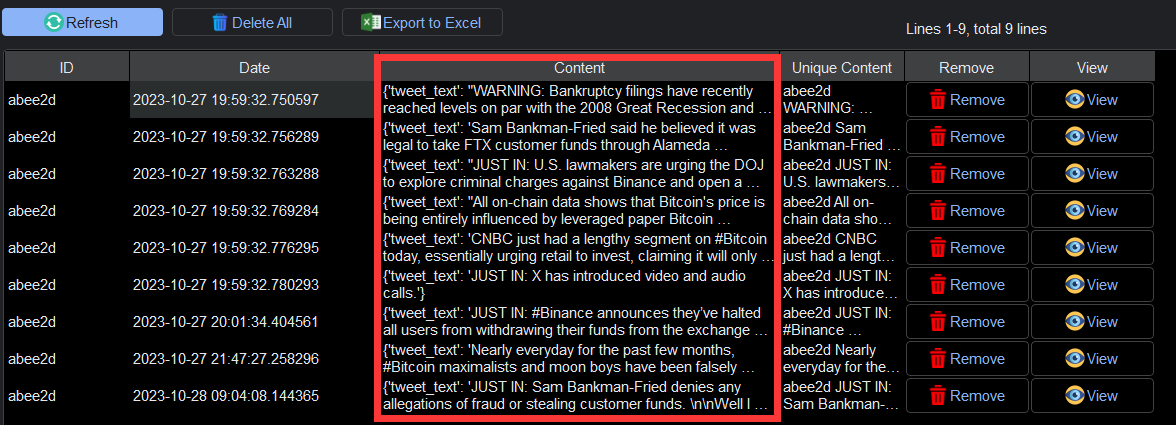
Conclusion: YL Web Scraper, with its proxy-enabled capabilities, opens up a world of possibilities for data extraction from the web. By following these simple steps, you can harness the full potential of this powerful tool to gather the information you need, all while ensuring seamless access through a variety of proxies. Unlock the true potential of web scraping with YL Web Scraper today!