In today’s digital age, extracting data from websites has become an integral part of various industries. However, accessing information from secured, login-restricted pages has always been a challenge. YL Web Scraper, a cutting-edge software solution, aims to address this issue by providing a seamless way to gather data from any webpage, even those that require authentication.
Key Features of YL Web Scraper
-
Simple Input Process
- Begin by entering the target website’s URL into the intuitive YL Web Scraper interface.
-
XPath Customization
- Specify exactly which elements on the webpage you want to extract using the powerful XPath language. This ensures that you capture the precise data you need.
-
Secure Login Capabilities
- YL Web Scraper is uniquely designed to access login-protected web pages. This means you can collect data from platforms that require authentication, expanding your ability to gather valuable insights.
-
Cookie-Based Authentication
- To facilitate access to secured content, YL Web Scraper allows you to retrieve the necessary cookies by logging in through the software. This step is crucial for seamless data extraction from protected websites.
-
Effortless Data Retrieval
- Once authenticated, YL Web Scraper seamlessly gathers the specified data, making it readily available for analysis.
Step-by-Step Guide: Extracting Data from Logged-In Websites
Follow these steps to effortlessly collect data from websites that require login credentials using YL Web Scraper:
-
Input the URL
- Open YL Web Scraper, Click Add Task and then input the URL of the website you wish to extract data from. This serves as the starting point for the data collection process.
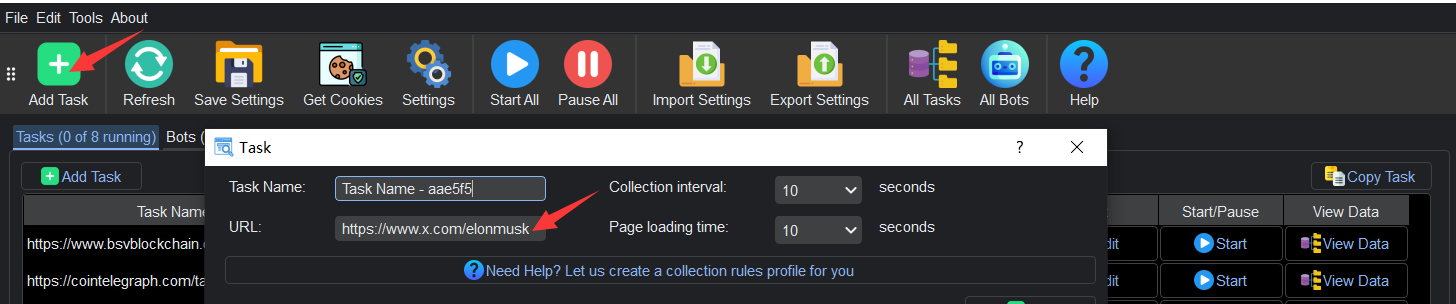
- Open YL Web Scraper, Click Add Task and then input the URL of the website you wish to extract data from. This serves as the starting point for the data collection process.
-
Define XPath Queries
- Using the XPath language, specify the elements on the webpage that you want to capture. This ensures that YL Web Scraper focuses on extracting the exact information you require.
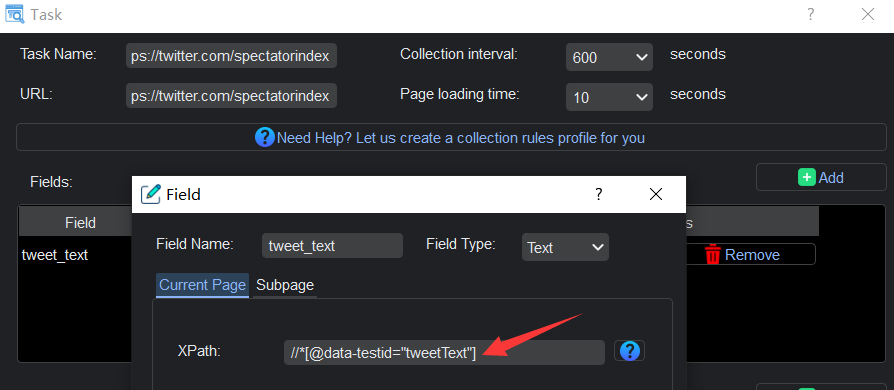
- Using the XPath language, specify the elements on the webpage that you want to capture. This ensures that YL Web Scraper focuses on extracting the exact information you require.
-
Login and Retrieve Cookies
- For websites that demand authentication, YL Web Scraper provides a seamless solution. Simply log in through the software, allowing it to retrieve the necessary cookies for secure access.
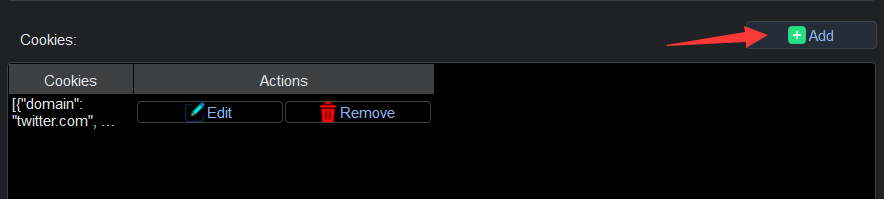
- For websites that demand authentication, YL Web Scraper provides a seamless solution. Simply log in through the software, allowing it to retrieve the necessary cookies for secure access.
-
Initiate Data Extraction
- With the authentication process completed, YL Web Scraper now proceeds to collect the specified data. The software efficiently navigates through the webpage, retrieving the targeted elements.

- With the authentication process completed, YL Web Scraper now proceeds to collect the specified data. The software efficiently navigates through the webpage, retrieving the targeted elements.
-
View and Analyze Data
- Once the data extraction process is complete, you can easily view and analyze the collected information within YL Web Scraper. This allows for further processing or exportation as needed.
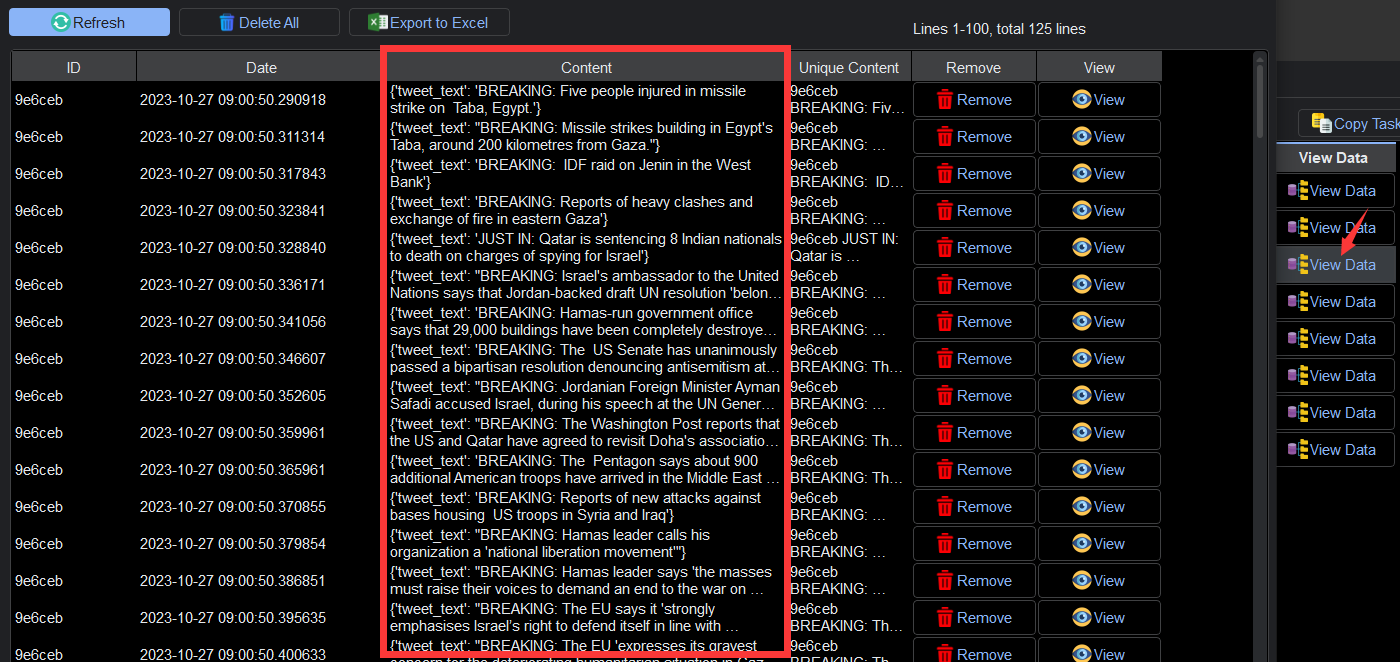
- Once the data extraction process is complete, you can easily view and analyze the collected information within YL Web Scraper. This allows for further processing or exportation as needed.
Conclusion
YL Web Scraper revolutionizes the process of gathering data from login-protected websites. Its seamless integration of XPath customization and cookie-based authentication enables users to effortlessly access and extract valuable information from a wide range of online platforms. By simplifying this once-complex task, YL Web Scraper empowers businesses and individuals to make informed decisions based on accurate, up-to-date data.